




Содержание
Перейти к:
https://doi.org/10.14341/DM12665
Перейти к:
В обзоре представлены возможности применения искусственного интеллекта для изучения механизмов развития сахарного диабета (СД) и создания новых технологий его профилактики, мониторинга и лечения. В последние годы накоплен огромный массив молекулярных данных, раскрывающих патогенетические механизмы развития СД и его осложнений. Интеллектуальный анализ данных и текстов научных публикаций (data mining и text mining) открывает новые возможности для обработки этой информации. Анализ молекулярно-генетических сетей позволяет выявить молекулярные взаимодействия, важные для развития СД и его осложнений, а также идентифицировать новые таргетные молекулы. На основе анализа больших данных и машинного обучения созданы новые платформы для прогноза и скрининга СД, диабетической ретинопатии, хронической болезни почек, сердечно-сосудистых осложнений. Алгоритмы машинного обучения применяются для персонифицированного прогноза уровня глюкозы, создания систем введения инсулина с замкнутым контуром, а также систем поддержки принятия решений по модификации образа жизни и лечению СД. Представляется перспективным применение интеллектуальных систем для анализа больших баз данных, регистров, исследований в реальной клинической практике. Внедрение систем, основанных на искусственном интеллекте, соответствует глобальным трендам современной медицины, в числе которых переход к цифровым и дистанционным технологиям, персонификация лечения, высокоточное прогнозирование и пациентоориентированный подход. Очевидна необходимость дальнейших исследований в этом направлении, с оценкой клинической эффективности новых технологий и их экономическим обоснованием.
Климонтов В.В., Бериков В.Б., Сайк О.В. Искусственный интеллект в диабетологии. Сахарный диабет. 2021;24(2):156-166. https://doi.org/10.14341/DM12665
Klimontov V.V., Berikov V.B., Saik O.V. Artificial intelligence in diabetology. Diabetes mellitus. 2021;24(2):156-166. (In Russ.) https://doi.org/10.14341/DM12665
Искусственный интеллект (ИИ, англ. artificial intelligence) — наука и технология создания интеллектуальных систем, т.е. систем, способных выполнять функции, ранее свойственные только человеку: в их числе способность правильно интерпретировать внешние данные, извлекать уроки из таких данных и использовать полученные знания для достижения конкретных целей и задач при помощи гибкой адаптации. ИИ и системы, на нем основанные, являются одним из важнейших научных достижений современной эпохи. Даже в повседневной жизни человек сталкивается с множеством вещей, так или иначе связанных с ИИ: голосовой помощник в мобильном устройстве, «умные» часы, компьютерные шахматы и т.д. В последние годы ИИ проникает во все сферы жизни человека, в том числе в медицину. Анализ базы данных Web of Science показал рост числа публикаций, посвященных применению ИИ в биомедицинских исследованиях: начиная с 1995 г. годовой прирост составил в среднем 17%, в период с 2014 по 2019 гг. — около 45%. Наиболее часто ИИ применяется в изучении рака, депрессии, болезни Альцгеймера, сердечной недостаточности и сахарного диабета (СД) [1].
Целью данного обзора стал анализ возможностей и основных достижений в изучении патогенеза СД, совершенствовании методов его профилактики, скрининга и лечения с помощью ИИ. Поиск источников проведен по ключевым словам “artificial intelligence” и “diabetes” в базе данных Pubmed/Medline. Учитывая большой объем работ по проблеме, мы приводим в основном результаты исследований последних 5 лет.
Возникновение ИИ связано с созданием электронно-механических устройств, поведение которых может быть запрограммировано с помощью набора некоторых правил, применяемых в соответствии с входными данными и внутренней логикой действий. Необходимость в системах ИИ была обусловлена появлением в 40–50-х гг. XX в. задач, которые было трудно или невозможно решить человеку, но которые были вполне под силу электронным устройствам того времени: расшифровка секретных сообщений противника, планирование военных операций и т.п. Дальнейшее развитие ИИ получило теоретическую базу в виде фундаментальных работ А. Тьюринга, К. Шеннона, Дж. Маккарти, Ф. Розенблатта и других исследователей, в которых были сформулированы основные положения теории алгоритмов, машинного обучения (МО), теории информации, искусственных нейронных сетей, языков программирования. Элементная база систем ИИ постоянно совершенствовалась (от электронных ламп — к транзисторам, затем к интегральным микросхемам), позволяя решать все более сложные задачи.
В ходе развития ИИ сформировались различные направления, среди которых можно отметить несколько основных [2]. Исторически одними из первых возникли символьный и логический подходы, в которых предполагается, что объекты реального мира, данные, знания могут быть формализованы некоторыми символами и операциями с ними, выражаемыми на языке математической логики. Для конкретных применений логического подхода были разработаны языки логического программирования. В основе агентоориентированного подхода лежит понятие агента как некоторой самообучающейся системы, которая может воспринимать сигналы окружающей среды и воздействовать на эту среду, чтобы оптимизировать определенные показатели качества. Статистическое обучение на основе примеров предполагает, что имеющиеся данные содержат скрытые закономерности, обнаружение и анализ которых позволяют строить прогнозы и принимать решения. В данном подходе, известном как МО или интеллектуальный анализ данных (ИАД), широко используются аппарат теории вероятностей и математической статистики, методы оптимизации.
В зависимости от способа задания целевого признака рассматривают следующие типы задач МО.
1. Обучение «с учителем» (supervised learning). Применяется, когда требуется по исходной выборке, а также по значениям целевого признака, указанного для всех ее элементов, построить решающее правило (прогнозную модель). В зависимости от типа целевого признака различают задачи регрессионного анализа, где прогнозируемый признак может принимать вещественные значения, и классификации (распознавания образов), где целевой признак — это некоторая метка класса, принадлежащая множеству нечисловой природы. В задачах, учитывающих фактор времени, необходимо прогнозировать значение целевого признака в будущие моменты.
2. Обучение «без учителя» (unsupervised learning). В этом случае целевой признак не указан; в эту группу задач включают кластерный анализ, где требуется разбить множество наблюдений на однородные группы, и задачи снижения размерности, в которых нужно сформировать систему признаков меньшей размерности, не потеряв при этом существенной информации.
3. Полуавтоматическое обучение (semi-supervised learning). Данный метод применяется, когда обучающая информация в виде набора значений целевого признака имеется лишь для части выборки, как правило, сравнительно малого объема.
Существует несколько основных подходов к решению задач МО1 (рис. 1). Вероятностный подход основан на представлении о том, что данные получены в соответствии с некоторым вероятностным распределением. Модель распределения может быть оценена по наблюдениям и использована для получения оптимальных решений (например, дающих минимальную оценку вероятности ошибки распознавания образов). В данном подходе широко применяется байесовский вывод, основанный на вычислении по формуле Байеса апостериорных вероятностей классов по известным априорным вероятностям и модели распределения. В «наивном» байесовском классификаторе (Naive Bayes; NB) предполагается статистическая независимость признаков. При исследовании процессов, изменяющихся во времени, используют понятие марковских цепей, в которых моделируются случайные переходы некоторой системы на множестве дискретных состояний.
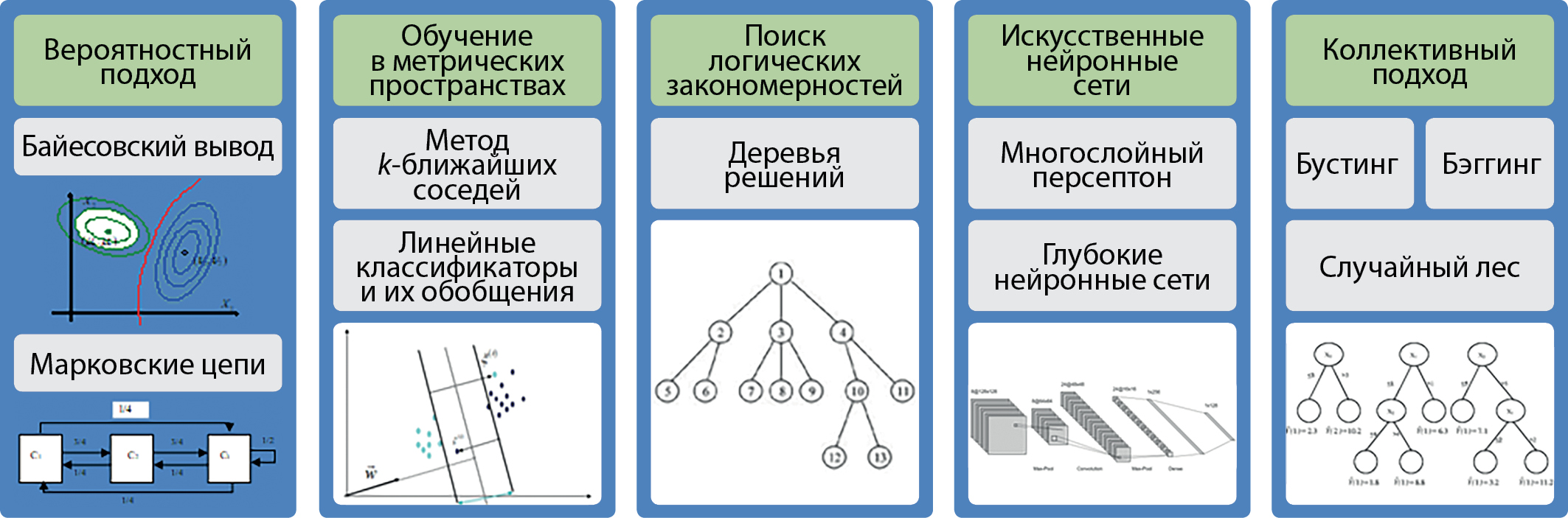
Рисунок 1. Основные подходы в машинном обучении.
Метрический подход применим для числовых признаков и использует аналогию с геометрическими точками, представляющими исходную выборку в многомерном евклидовом пространстве. Прогнозное решение принимается путем анализа метрических свойств выборки, например, с помощью поиска наиболее близких точек в методе k ближайших соседей (k-Nearest Neighbors; k-NN). К этому же подходу можно отнести линейные классификаторы, основанные на поиске оптимальной разделяющей гиперплоскости (линейный дискриминант Фишера); метод опорных векторов (Support Vector Machine; SVM), в котором ищется полоса максимальной ширины, разделяющая точки различных классов, а также обобщения этого метода на случай задачи регрессионного анализа (Support Vector Regression; SVR) и линейно неразделимых классов (SVM с использованием ядра); линейный регрессионный анализ и его обобщения; модель логистической регрессии (Logistic Regression; LR).
Следующий подход основан на поиске логических закономерностей в данных и использовании закономерностей при принятии решений. Удобной формой представления закономерностей является дерево решений (Decision Tree; DT), представляющее собой наглядную иерархическую модель изучаемой зависимости. При формировании DT проводятся поэтапный отбор наиболее важных предикторов и автоматический отсев шумовых, неинформативных признаков. Достоинством этого подхода является то, что он позволяет проводить анализ как числовых, так и нечисловых атрибутов.
Одной из основных технологий обучения являются искусственные нейронные сети (Artificial Neural Networks; ANN), в частности, многослойный персептрон (Multilayer Perceptron), моделирующие функционирование биологических нейронов при обработке поступающих на них сигналов. В последнее время активно развиваются глубокие нейронные сети, демонстрирующие значительный прогресс в распознавании зрительных образов и обработке естественной речи (Natural Language Processing; NLP) [3]. Применяются различные архитектуры глубоких ANN, такие как сверточные сети (Deep Convolutional Networks), основанные на применении линейного преобразования, — свертки; глубокие рекуррентные сети (Recurrent Neural Networks), служащие для моделирования различных последовательностей, и т.д.
Коллективный (ансамблевый) подход в МО позволяет использовать преимущества различных алгоритмов, входящих в ансамбль, для повышения прогнозирующей способности решений. Существуют адаптивные методы построения ансамбля (называемые бустингом; boosting) и методы, в которых базовые решения формируются случайным образом независимо друг от друга (бэггинг; bagging). Хорошо зарекомендовали себя методы бустинга деревьев решений и метод случайного леса (Random Forest; RF), в качестве базовых элементов использующие DT, генерируемые по случайным подвыборкам.
Для нахождения оптимальных решений в МО используются современные методы оптимизации, такие как метод стохастического градиента (Stochastic Gradient Descent) при обучении нейронных сетей, генетическое и эволюционное программирование, позволяющие эффективно решать сложные оптимизационные задачи при анализе больших массивов данных [4][5].
Ниже мы рассмотрим результаты применения указанных подходов к изучению СД.
Омиксные технологии и анализ молекулярно-генетических сетей. Появление геномики, транскриптомики, протеомики и метаболомики определило информационный взрыв в биомедицине: информация о генах, белках, сигнальных и метаболических путях, ассоциированных с заболеваниями человека, стала увеличиваться лавинообразно. При этом стало очевидно, что для понимания природы таких сложных мультифакториальных заболеваний, как СД, недостаточно идентифицировать отдельные молекулярно-генетические признаки — для формирования целостного представления о патогенезе заболевания необходимо учитывать взаимодействия многочисленных молекул между собой. Комплексный анализ молекулярно-генетических сетей с помощью ИИ позволяет более полно раскрывать механизмы патологических состояний. Молекулярно-генетическая (генная) сеть — это группа координированно функционирующих генов, взаимодействующих друг с другом через свои первичные продукты (РНК и белки), а также через разнообразные метаболиты и другие вторичные продукты [6]. Генные сети часто изображают в виде графа, где вершинами являются биологические объекты (гены, белки, РНК, метаболиты и др.), а ребрами — взаимосвязи между ними. В ряде исследований выполнены реконструкция и анализ молекулярно-генетических сетей СД с привлечением ИИ.
Биоинформационный анализ сетей взаимодействий белок–белок с использованием наивного байесовского классификатора [7], а также метод «случайного блуждания» (Random Walk) по мультиграфу ассоциативной сети, объединяющей гетерогенные геномные и фенотипические данные [8], позволил выявить наиболее приоритетные гены, в том числе новые гены-кандидаты, для СД 1 типа. Алгоритм распространения меток (Label Propagation Algorithm), применяемый, например, для ранжирования страниц в поисковой системе Google, был использован для приоритизации генов-кандидатов, потенциально вовлеченных в развитие СД 2 типа, выявленных в полногеномных исследованиях. Для обучения использовалась масштабная генная сеть, включающая функциональные взаимодействия генов человека [9]. Модифицированный метод частичных наименьших квадратов (PLS) был использован для построения комбинированной молекулярной сети, содержащей гены и метаболиты. Топологический анализ данной сети позволил выявить тканеспецифичную генетическую регуляцию метаболома и транскриптома в модели экспериментального СД 2 типа [10]. Основываясь на различиях в уровнях экспрессии генов в трех тканях-мишенях инсулина (белой жировой ткани, скелетных мышцах и печени), была реконструирована генная сеть, ассоциированная с СД 2 типа. Метод случайного блуждания позволил выявить участников сети, наиболее тесно связанных с СД в каждой ткани [11]. Интеллектуальный анализ данных (data mining) метилирования ДНК при СД 2 типа позволил реконструировать генную сеть, ассоциированную с инсулинорезистентностью и депрессией, в центре которой оказался ген рецептора витамина D (VDR). С помощью логистической регрессии было показано, что идентификация статуса метилирования определенных областей промотора гена VDR может помочь стратифицировать пациентов, для которых употребление витамина D может принести максимальную пользу [12].
Накапливается информация о белках и белок–белковых взаимодействиях, важных для развития СД. База данных KEGG (the Kyoto Encyclopedia of Genes and Genomes) содержит информацию о 34 белках, в отношении которых имеются экспериментальные доказательства их вовлеченности в патогенез СД. Мультипараметрический биоинформационный анализ предсказал, что белки IRS1, IRS2, IRS4, MAFA, PDX1, ADIPO, PIK3R2, PIK3R5, SoCS1 и SoCS3 являются внутренне неупорядоченными, то есть не имеют жестко фиксированной трехмерной структуры и представляют собой динамический набор взаимопревращающихся вариантов структур. Белки VDCC, SoCS2, SoCS4, JNK9, PRKCZ, PRKCE, инсулин, GCK, JNK8, JNK10, PYK, INSR, TNF-α, MAPK3 и Kir6.2 были классифицированы как умеренно неупорядоченные (от 10 до 30% аминокислотных остатков входят в неупорядоченные участки белка). В число в основном упорядоченных белков, имеющих менее 10% неупорядоченных участков, попали GLUT2, GLUT4, mTOR, SUR1, MAPK1, IKKA, PRKCD, PIK3CB и PIK3CA. Внутренне неупорядоченные участки белков часто являются функционально значимыми, так как принимают участие в белок–белковых взаимодействиях или несут сайты посттрансляционных модификаций. При заболеваниях динамическое равновесие вариантов структур внутренне неупорядоченных белков может смещаться, провоцируя различные патологические процессы [13]. Применение метода SVM, текст-майнинга биомедицинских публикаций и ANN позволило идентифицировать белок–белковые взаимодействия, важные для развития СД, а также идентифицировать новые таргетные молекулы для будущих терапевтических воздействий [14].
Интеллектуальный анализ данных и текстов научных публикаций. В настоящее время созданы тысячи баз данных, содержащих биологическую, медицинскую, фармакологическую, химическую информацию, в том числе по СД. Например, в базе данных PubMed представлено более 30 млн рефератов (абстрактов) научных статей, из них более чем в 700 тысячах упоминается СД. Анализ такого объема информации невозможен без эффективных методов автоматического извлечения знаний из баз данных и текстов научных публикаций (data mining, text mining).
Интеллектуальный анализ текстов является примером применения ИИ для анализа больших объемов информации. Данный подход позволяет преобразовать неструктурированные текстовые данные в значимую полезную информацию, пригодную для дальнейшего автоматического или ручного анализа. Текст-майнинг, как правило, включает в себя поиск релевантных источников информации, лингвистический анализ текстов, распознавание названий объектов и взаимодействий между ними, извлечение и хранение информации, методы визуализации и дальнейший анализ полученных данных. Один из разделов данного анализа, активно используемый в области биомедицины, подразумевает извлечение из текстов биомедицинских понятий/сущностей и отношений между ними с последующим представлением в виде графов молекулярно-генетических сетей. Примером интеллектуальных систем, используемых для текст-майнинга, является компьютерная система ANDSystem, созданная российскими специалистами [15][16]. База данных этой системы содержит более 40 млн фактов, извлеченных из 28 млн рефератов Medline, которые описывают генетическую регуляцию, белок–белковые взаимодействия, каталитические реакции, транспортные пути, ассоциации генов, белков, метаболитов с заболеваниями, фенотипами и биологическими процессами. Схематично технология работы ANDSystem представлена на рис. 2. Проведенный нами с помощью системы ANDSystem интеллектуальный анализ текстов научных публикаций обнаружил 488 генов, связанных с СД 2 типа. Среди них для 140 генов описаны мутации, ассоциированные с риском развития заболевания, для остальных 348 генов показано изменение экспрессии, активности или концентрации их продуктов (рис. 3). Реконструкция и анализ молекулярно-генетической сети вариабельности гликемии позволили выделить 37 генов, связанных одновременно и с высоким, и с низким уровнем глюкозы. Продукты данных генов вовлечены в секрецию инсулина, метаболизм глюкозы, биосинтез гликогена, глюконеогенез, сигнальные пути MAPK и JAK-STAT, пролиферацию клеток, биосинтез оксида азота и другие биологические процессы. Оказалось, что гены, связанные с вариабельностью гликемии, занимают центральные позиции в молекулярно-генетических сетях микрососудистых и макрососудистых осложнений СД [17].

Рисунок 2. Схематичное представление работы системы ANDSystem для интеллектуального анализа текстов научных публикаций.
На вход система ANDSystem принимает тексты рефератов научных статей из Medline, из которых в ходе автоматического интеллектуального анализа текстов извлекаются взаимодействия между биологическими объектами. Выявленная информация хранится в базе данных ANDCell. По запросу пользователя с помощью модуля ANDVisio, предназначенного для визуализации и анализа данных, могут быть реконструированы молекулярно-генетические сети, основанные на информации из базы данных ANDCell.

Рисунок 3. Ассоциативная генная сеть сахарного диабета 2 типа, построенная с помощью системы ANDSystem.
В выносках представлены примеры предложений с указанием идентификаторов PubMed рефератов статей, из которых была извлечена информация о взаимодействиях генов/белков с СД 2 типа. Штриховыми линиями показаны примеры предложений, описывающих ассоциации мутаций с риском СД 2 типа. Сплошными линиями обозначены предложения, где говорится об изменениях экспрессии, активности или концентрации генов и их продуктов при СД 2 типа.
В Китае на основе майнинга сети создана база данных по СД, содержащая данные о симптомах заболевания, методах его лечения, применяемых в западной и традиционной китайской медицине, ассоциированных заболеваниях и проч. [18].
Таким образом, использование ИИ открывает широкие возможности для изучения молекулярных основ развития СД, а также поиска новых прогностических маркеров и таргетных молекул для будущих терапевтических воздействий.
Модели прогноза и скрининга СД. Методы ИИ (в частности, МО) используются в медицине для создания моделей, позволяющих классифицировать обследуемых по состоянию здоровья, выявить факторы риска и вероятность развития заболеваний. В одном из недавних исследований для создания прогностических моделей СД 2 типа были применены различные методы МО, включая SVM, DT, LR, RF, ANN, наивный байесовский классификатор с применением гауссовской модели распределения (Gaussian NB). Данные 138 146 американцев, включая 20 467 больных СД 2 типа, были использованы для моделирования. Из 8 созданных моделей ANN давала наибольшие значения площади под операционной кривой; однако модель DT оказалась предпочтительней для скрининга СД 2 типа из-за большей чувствительности. Помимо общеизвестных факторов риска СД, длительность сна и частота медицинских обследований были идентифицированы как два новых потенциальных предиктора [19]. В другом исследовании, выполненном в Канаде, модели градиентного бустинга (Gradient Boosting Machine) и LR давали более точный прогноз развития СД 2 типа по сравнению с RF и DT [20]. В работе китайских исследователей [21] комбинация результатов 5 алгоритмов МО, основанных на многослойном персептроне, алгоритме бустинга деревьев решений AdaBoost, случайном лесе решений, методе опорных векторов и градиентном бустинге деревьев решений, давала наилучший результат в оценке риска СД 2 типа.
Показана эффективность алгоритмов случайного леса, градиентного бустинга и бэггинга в идентификации и ранжировании кардиометаболических факторов риска [22]. В одном из недавних исследований американская база данных NHANES (the National Health and Nutrition Examination Survey) и различные методы МО (LR, SVM, RF и градиентный бустинг) были использованы для моделирования риска сердечно-сосудистых заболеваний, предиабета и СД. Наиболее значимыми предикторами СД оказались: окружность талии, возраст, масса тела, длина ноги и потребление натрия [23]. Показана эффективность технологий МО в эпидемиологической оценке особенностей питания, ассоциированных с риском развития сердечно-сосудистых заболеваний, СД, артериальной гипертензии и гиперхолестеринемии [24].
Несомненный интерес представляют исследования, в которых ИИ используется для создания технологий ранней диагностики и скрининга СД 2 типа. Технология МО (модификация метода опорных векторов: sparse balanced SVM) и данные итальянской электронной базы данных общей врачебной практики были использованы для создания идентификатора лиц с СД. Полученная с помощью МО модель давала наиболее точный результат по сравнению с другими методами статистического моделирования [25]. Два алгоритма бустинга (Adaboost.M1 и LogitBoost) были использованы для создания технологии диагностики СД. Проанализированы клинические данные 35 669 человек. Созданная модель смогла идентифицировать больных СД с высокой точностью: площадь под ROC-кривой составила 0,99 [26].
Созданные с помощью ИИ системы можно использовать для выявления потенциальных пациентов с СД в популяционных выборках и больших электронных базах данных. Для телемедицинского консультирования и прескрининга СД могут применяться интеллектуальные системы, способные понимать речь и дистанционно взаимодействовать с человеком [27].
Модели прогноза и скрининга осложнений СД. Наибольшее количество исследований в этой области посвящено диабетической ретинопатии (ДР). С помощью алгоритмов глубокого МО разработаны идентификаторы, оценивающие выраженность изменений на фотографиях глазного дна и классифицирующие ДР на стадии [28–30]. Применение этих классификаторов повышает точность и объективность диагностики осложнения. Метаанализ 8 исследований, изучавших эффективность алгоритмов глубокого МО в распознавании ДР, продемонстрировал их высокую чувствительность (74%) и специфичность (95%) [31]. В масштабном исследовании [32], включавшем 2680 больных СД 1 и 2 типа, проведена валидация алгоритма скрининга ДР, основанного на ИИ (IDx-DR), в реальной клинической практике. По сравнению со стандартной диагностикой автоматизированная система оценки изображений позволяла идентифицировать ДР с чувствительностью и специфичностью в 100% и 82,8%. С помощью технологии искусственных нейронных сетей разработана система оценки изображений сетчатки, полученных без расширения зрачка с помощью фундус-камеры, установленной на смартфон. Подобный подход может использоваться как первый этап скрининга ДР, который можно провести еще до контакта со специалистом. Сравнение результатов работы алгоритма со стандартизированными диагностическими заключениями офтальмологов показало высокую чувствительность (83,3%) и специфичность (95,5%) разработанного алгоритма [33]. Таким образом, применение технологий ИИ способствует автоматизации скрининга ДР, что в перспективе повысит его доступность, позволит уменьшить нагрузку на офтальмологов, увеличит возможности диагностики в дистанционном режиме.
ИАД и МО (алгоритмы RF и LR) были использованы для выявления клинических факторов, связанных с прогрессированием поражения почек у больных СД 2 типа, принимавших участие в исследовании ACCORD (the Action to Control Cardiovascular Risk in Diabetes). Исходные значения скорости клубочковой фильтрации, креатинина и альбумина мочи, соотношение альбумин/креатинин мочи, уровни калия, холестерина и липопротеинов низкой плотности были идентифицированы как предикторы прогрессирования хронической болезни почек (ХБП). Ранними предикторами (в период до 2 лет) оказались скорость клубочковой фильтрации, систолическое артериальное давление, глюкоза плазмы натощак и калий. Ежегодная динамика клубочковой фильтрации, глюкоза плазмы натощак и триглицериды указывали на риск прогрессирования ХБП в более отдаленной перспективе (до 7 лет) [34]. На основе анализа данных 64 059 пациентов, с применением NLP и МО на лонгитюдных данных большого объема, разработана предиктивная модель ХБП, оперирующая 3073 признаками. Применение модели позволило предсказать прогрессирование ХБП у больных СД с точностью 71% [35]. В рамках проекта MOSAIC с помощью ИАД разработаны модели, позволяющие прогнозировать развитие ДР, нефропатии и нейропатии у больных СД 2 типа с точностью до 83,8% [36].
Глубокое МО нашло применение при разработке нового высокоточного метода диагностики диабетической нейропатии с помощью конфокальной томографии роговицы. Метод предполагает количественную оценку морфологии нервных волокон роговицы с помощью алгоритма, использующего сверточные нейронные сети и аугментацию данных2. Чувствительность алгоритма в диагностике нейропатии составила 68%, специфичность — 87% [37].
На основе анализа данных 423 604 лиц, включенных в биобанк Великобритании, разработана модель оценки сердечно-сосудистого риска. Модель, созданная с помощью МО и оперирующая 473 характеристиками, давала более точный прогноз развития сердечно-сосудистых заболеваний по сравнению с хорошо известной Фрамингемской шкалой. Улучшение достоверности прогноза было достигнуто и для больных СД [38].
Таким образом, в настоящее время ИИ широко применяется для создания технологий прогнозирования и скрининга СД и его осложнений. Системы ИИ могут быть созданы на основе анализа больших объемов информации (национальных баз данных, регистров, результатов популяционных исследований и проч.). В свою очередь, системы, разработанные на больших данных, обычно оказываются валидными при применении к выборкам меньшего размера [39].
Прогнозирование гликемии. Системы ИИ нашли применение в изучении закономерностей динамики и прогнозировании гликемии у больных СД. Известно, что прогнозировать гликемию по физиологическим данным достаточно сложно из-за большого количества факторов, влияющих на уровень глюкозы в крови. Этим фактом можно объяснить многообразие математических моделей, предложенных для описания регуляции и прогнозирования гликемии у больных СД [40].
Системы ИИ (в частности, МО) дают возможность строить прогноз «поведения» гликемии у конкретного пациента по предыдущим накопленным данным. Обучение системы происходит на основе результатов непрерывного мониторинга глюкозы (НМГ), флэш-мониторинга глюкозы в интерстициальной жидкости или (реже) самоконтроля глюкозы в капиллярной крови. Объектом прогноза может быть уровень глюкозы как таковой или же то или иное отклонение («событие»): гипогликемия, постпрандиальная гипергликемия и проч. Большинство разработанных на сегодняшний день систем прогнозируют уровень глюкозы с горизонтом до 5 до 180 мин [41].
На эффективность технологий прогнозирования влияют количество и качество данных, используемых для «обучения», а также метод МО. Показано, что для краткосрочного (с горизонтом 15 мин) прогноза уровня глюкозы с ошибкой около 0,86 ммоль/л достаточно 24 ретроспективных значений, полученных в течение 6 ч. При включении в анализ 72 значений глюкозы ошибка прогноза снижается до 0,56 ммоль/л [42]. Первые системы прогнозирования гликемии, предложенные в 2010–2012 гг., были разработаны с использованием ANN [41]. В последующие годы для этой задачи были апробированы и другие методы МО, включая RF, генетическое программирование, k-NN, эволюционное программирование с использованием грамматического анализа [43], Gaussian NB, алгоритм бустинга AdaBoost, SVM и ANN [44], рекурсивную нейронную сеть, использующую блоки долгой краткосрочной памяти [45], модель SVR [46] и проч. Показано, что разные методы МО могут обеспечивать различную точность прогноза в зависимости от того, в каком диапазоне уровня глюкозы (гипогликемии, нормогликемии или гипергликемии) находится прогнозируемое «событие». Так, в работе [47] модель SVR, обученная как на исходных признаках, так и на признаках, полученных с помощью полиномиального преобразования, являлась наилучшей для прогнозирования значений глюкозы в целевом диапазоне и в диапазоне гипергликемии, в то время как многослойный персептрон, обученный на искусственно пополненных данных, был оптимальным для прогнозирования гипогликемии. Для прогноза постпрандиальной гипогликемии у больных СД 1 типа наилучшей оказалась модель, основанная на алгоритме RF, по сравнению с SVM, использующим линейное или RBF-ядро, алгоритмами k-NN и LR [48].
Несмотря на ряд нерешенных проблем, полученные с помощью ИИ модели дают возможность прогнозировать уровень глюкозы в краткосрочной перспективе с клинически приемлемой точностью. Так, алгоритмы прогнозирования постпрандиальной гипогликемии у больных СД 1 типа, получающих инсулин с помощью помпы с функцией НМГ, предсказывали уровень глюкозы ниже 3 ммоль/л с чувствительностью и специфичностью 77% и 81% соответственно [49]. Созданные при помощи МО программы могут быть установлены на мобильные устройства (смартфон или одноплатный компьютер), обеспечивая прогнозирование гликемии в режиме “On the Fly” («на лету») [50].
Системы автоматического введения инсулина с замкнутым контуром. Создание адекватных алгоритмов (моделей) прогноза гликемии, учитывающих индивидуальные особенности пациента, является необходимым условием для персонификации инсулинотерапии. Алгоритмы высокоточного прогнозирования уровня глюкозы незаменимы для создания систем введения инсулина с замкнутым контуром («искусственной поджелудочной железы»). В этих системах алгоритмы работают с данными НМГ в режиме реального времени. На основании предсказанных значений гликемии помпа проводит инфузию инсулина с заданной скоростью. В настоящее время на российском рынке доступна помпа Medtronic Minimed™ G640, которая останавливает введение инсулина при возникновении тренда к гипогликемии (технология SmartGuard); после устранения угрозы гипогликемии введение инсулина возобновляется. Клинические исследования показали значительное снижение числа эпизодов гипогликемии у детей и взрослых с СД 1 типа при использовании данной помпы [51][52].
Следующим шагом стало создание гибридных систем введения инсулина, автоматически регулирующих базальную скорость подачи инсулина в зависимости от предшествующего и актуального уровня глюкозы. Первая коммерчески доступная помпа такого типа (MiniMed™ 670G; Medtronic) была зарегистрирована FDA в 2016 г. Алгоритм работы данной помпы предполагает также минимизацию риска постпрандиальной гипогликемии. Использование помпы позволяет увеличить время в целевом диапазоне глюкозы и уменьшить HbA1c у больных СД 1 типа [53], в том числе при переводе с помпы Minimed™ G640 [54]. Начиная с 2017 г., еще 4 гибридных системы с замкнутым контуром были одобрены для клинического применения регуляторными органами разных стран3. Заметим, что все эти системы не являются полностью автоматизированными, поскольку требуют введения в ручном режиме болюсов инсулина для контроля постпрандиальной гликемии [55].
Алгоритмы последующих поколений обеспечивают не только коррекцию скорости базальной подачи инсулина, но и автоматический расчет пищевых и корректирующих болюсов, а также возможность индивидуального выбора целевого уровня глюкозы. Работа таких алгоритмов направлена на максимально полную имитацию физиологической секреции инсулина. В бигормональных системах гликемия поддерживается введением инсулина и глюкагона. В условиях in silico алгоритмы на основе ИИ способны обеспечивать практически круглосуточное поддержание нормогликемии (время в целевом диапазоне около 90%) [56]. В настоящее время проводятся многоцентровые клинические исследования, направленные на изучение эффективности и безопасности систем с замкнутым контуром у пациентов с СД 1 типа.
Системы поддержки принятия решений (СППР). Алгоритмы, созданные с помощью ИИ, могут быть инкорпорированы в автоматические СППР, которые дают рекомендации по диете, физической активности, сахароснижающей терапии и другим аспектам лечения СД. Одним из первых в этом направлении стал METABO — мультидисциплинарный проект, финансируемый Европейским Союзом, направленный на развитие цифровых технологий в диабетологии, в том числе создание СППР для пациентов с СД 1 и 2 типов [57]. Системы могут быть ориентированы на врачей, пациентов или организаторов здравоохранения. На рис. 4 представлен пример СППР в области фармакотерапии СД 2 типа.

Рисунок 4. Фрагмент системы поддержки принятия решений в области фармакотерапии сахарного диабета 2 типа.
Созданная с помощью текст-майнинга научных публикаций (система ANDSystem) ассоциативная сеть содержит информацию о лекарственных взаимодействиях между метформином и другими препаратами. Нажав на стрелку, демонстрирующую взаимодействие, пользователь может получить информацию об эффекте взаимодействия со ссылками на соответствующие статьи.
Особо следует отметить СППР для пациентов, получающих инсулин. Такие системы могут быть нацелены как на более эффективную титрацию доз инсулина, так и на предупреждение эпизодов гипогликемии. Показано, что алгоритмы МО, созданные на основе данных самоконтроля гликемии, могут использоваться для коррекции болюсов прандиального инсулина (минимизации постпрандиальной гипергликемии) у больных СД 1 типа, получающих инсулинотерапию в режиме множественных инъекций [49]. На основе метода k-NN разработан алгоритм, идентифицирующий причины гипергликемии и гипогликемии и еженедельно предлагающий рекомендации по титрации дозы инсулина больным СД 1 типа [58]. Продемонстрирована эффективность технологии коррекции гликемии перед отходом ко сну, созданной с помощью МО на основе данных НМГ: технология позволила предупредить 94,1% эпизодов ночной гипогликемии у больных СД 1 типа [46].
СППР могут использоваться в телемедицине. Примером является MobiGuide — мобильная телемедицинская система для пациенток с гестационным СД, основанная на ИИ. Система аккумулирует клинические данные, результаты самоконтроля в индивидуальной медицинской карте, доступной пациенту и врачу. Анализируя уровень глюкозы, артериальное давление, особенности питания, физическую активность и другие данные, система сопоставляет их с заложенными в алгоритм компьютерными инструкциями и выдает медицинские рекомендации. Показано, что использование системы повышает приверженность самоконтролю у женщин с гестационным СД [59]. Использование системы удаленного наблюдения и поддержки для пациенток с гестационным СД Sinedie, оперирующей результатами самоконтроля глюкозы, кетонов, данными о питании и другой информацией, позволило сократить число визитов в клинику и время, затрачиваемое врачом на работу с одной пациенткой [60]. Alotaibi M.M. и соавт. разработана дистанционная интеллектуальная система для больных СД 2 типа, включающая алгоритм поддержки принятия решений и образовательный модуль. Тестирование системы у 20 пациентов в течение 6 мес показало снижение уровня гликированного гемоглобина и улучшение осведомленности пациентов о заболевании [61].
Анализ результатов клинических исследований и реальной клинической практики. Методы ИИ применяются для анализов результатов контролируемых клинических исследований. Так, с помощью МО идентифицированы характеристики больных СД 2 типа, ассоциированные со снижением или увеличением смертности на фоне интенсивной сахароснижающей терапии. ИАД (с использованием градиентного бустинга на деревьях решений) 10 291 участника исследования ACCORD показал, что наиболее благоприятное влияние на смертность при интенсификации сахароснижающей терапии следует ожидать у пациентов не старше 61 года, с индексом массы тела <30 кг/м2 и индексом гликирования гемоглобина <0,444 [63].
Особую роль ИИ играет в анализе исследований в условиях реальной клинической практики. Такие исследования, как правило, основаны на очень больших электронных базах данных. Примером может являться исследование LIGHTNING, предпринятое для моделирования, прогнозирования и оценки частоты эпизодов тяжелой гипогликемии у больных СД 2 типа, получающих лечение базальными аналогами инсулина человека. Для решения задач исследования была использована американская база данных Optum Humedica US, содержащая информацию о 831 456 потенциально подходящих пациентах. Исследование продемонстрировало, что частота эпизодов тяжелой гипогликемии у больных, впервые начавших терапию инсулинами гларгин 300 ЕД/мл или деглудек, на 50% ниже, чем у пациентов, получающих гларгин 100 ЕД/мл или детемир. С помощью МО разработана система прогнозирования тяжелой гипогликемии у больных СД 2 типа, получающих базальные аналоги инсулина [64, 65]. Другим примером является предиктивная модель, нацеленная на селективный отбор пациентов на бариатрические операции, созданная на основе анализа двух больших электронных баз данных реальной клинической практики в США [66].
Таким образом, ИИ становится важным инструментом в разработке новых высокотехнологичных и персонифицированных подходов к управлению и мониторингу СД.
Представленные данные свидетельствуют о перспективности использования систем ИИ в изучении механизмов развития СД, оптимизации методов его диагностики, профилактики и лечения. Уже сегодня ИИ стал незаменимым инструментом в анализе «больших данных» в области диабетологии, анализе результатов «омиксных» исследований, молекулярном профилировании заболевания. Алгоритмы анализа «поведения» гликемии, созданные с помощью ИИ, заложены в основу работы автоматизированных систем для введения инсулина. Представляется перспективным применение ИИ для анализа больших электронных баз данных, регистров СД, создания новых технологий диагностики и прогноза осложнений, дистанционного скрининга и мониторинга, разработки систем поддержки принятия решений, а также в исследованиях в условиях реальной клинической практики. Внедрение систем ИИ, безусловно, соответствует глобальным трендам современной медицины, в числе которых переход к цифровым и дистанционным технологиям, персонификация лечения, высокоточное прогнозирование, демократизация отношений в системах «врач — пациент», «общество — система здравоохранения». На наш взгляд, очевидна необходимость дальнейших исследований в этом направлении с оценкой клинической эффективности и экономическим обоснованием применения систем ИИ в диагностике, лечении и профилактике СД.
1. Заметим, что это деление не является четким; многие подходы взаимно проникают друг в друга или комбинируются между собой.
2. Под аугментацией понимается искусственное увеличение выборки путем применения операций поворота, отражения и извлечения частей изображений.
3. В России системы такого рода пока не зарегистрированы.
4. Индекс гликирования гемоглобина — разница между фактическим и прогнозируемым значениями HbA1c, где прогнозируемое значение рассчитывается по формуле: 0,009 × глюкоза плазмы натощак (мг/дл) + 6,8 [62].
1. Guo Y, Hao Z, Zhao S, Gong J, Yang F. Artificial Intelligence in Health Care: Bibliometric Analysis. J Med Internet Res. 2020;22(7):e18228. doi: https://doi.org/10.2196/18228
2. Рассел С., Норвиг П. Искусственный интеллект: современный подход. 2-е изд. Пер. с англ. — М.: ООО «И.Д. Вильямс»; 2016.
3. LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436-444. doi: https://doi.org/10.1038/nature14539
4. Flach P. Machine learning: the art and science of algorithms that make sense of data. Cambridge University Press; 2012.
5. Alpaydin E. Introduction to machine learning. MIT press; 2020.
6. Колчанов Н.А., Игнатьева Е.В., Подколодная О.А., и др. Генные сети // Вавиловский журнал генетики и селекции. — 2013. — T. 17. — №4/2. — С. 833-850.
7. Gao S, Jia S, Hessner MJ, Wang X. Predicting disease-related subnetworks for type 1 diabetes using a new network activity score. OMICS. 2012;16(10):566-78. doi: https://doi.org/10.1089/omi.2012.0029
8. Li Y, Li J. Disease gene identification by random walk on multigraphs merging heterogeneous genomic and phenotype data. BMC Genomics. 2012;13(S7):S27. doi: https://doi.org/10.1186/1471-2164-13-S7-S27
9. Lee I, Blom UM, Wang PI, et al. Prioritizing candidate disease genes by network-based boosting of genome-wide association data. Genome Res. 2011;21(7):1109-1121. doi: https://doi.org/10.1101/gr.118992.110
10. Dumas ME, Domange C, Calderari S, et al. Topological analysis of metabolic networks integrating co-segregating transcriptomes and metabolomes in type 2 diabetic rat congenic series. Genome Med. 2016;8(1):1-5. doi: https://doi.org/10.1186/s13073-016-0352-6
11. Sun S, Sun F, Wang Y. Multi-level comparative framework based on gene pair-wise expression across three insulin target tissues for type 2 diabetes. Front Genet. 2019;10:252. doi: https://doi.org/10.3389/fgene.2019.00252
12. Liang F, Quan Y, Wu A, et al. Insulin-resistance and depression cohort data mining to identify nutraceutical related DNA methylation biomarker for type 2 diabetes. Genes Dis. January 2020. doi: https://doi.org/10.1016/j.gendis.2020.01.013
13. Du Z, Uversky VN. A Comprehensive Survey of the Roles of Highly Disordered Proteins in Type 2 Diabetes. Int J Mol Sci. 2017;18(10):2010. doi: https://doi.org/10.3390/ijms18102010
14. Vyas R, Bapat S, Jain E, et al. Building and analysis of protein-protein interactions related to diabetes mellitus using support vector machine, biomedical text mining and network analysis. Comput Biol Chem. 2016;65:37-44. doi: https://doi.org/10.1016/j.compbiolchem.2016.09.011
15. Ivanisenko VA, Saik OV, Ivanisenko NV, et al. ANDSystem: an Associative Network Discovery System for automated literature mining in the field of biology. BMC Syst Biol. 2015;9(Suppl 2):S2. doi: https://doi.org/10.1186/1752-0509-9-S2-S2
16. Ivanisenko VA, Demenkov PS, Ivanisenko TV, et al. A new version of the ANDSystem tool for automatic extraction of knowledge from scientific publications with expanded functionality for reconstruction of associative gene networks by considering tissue-specific gene expression. BMC Bioinformatics. 2019;20(S1):34. doi: https://doi.org/10.1186/s12859-018-2567-6
17. Saik OV, Klimontov VV. Bioinformatic Reconstruction and Analysis of Gene Networks Related to Glucose Variability in Diabetes and Its Complications. Int J Mol Sci. 2020;21(22):E8691. doi: https://doi.org/10.3390/ijms21228691
18. Gong F, Chen Y, Wang H, Lu H. On building a diabetes centric knowledge base via mining the web. BMC Med Inform Decis Mak. 2019;19(S2):49. doi: https://doi.org/10.1186/s12911-019-0771-6
19. Nguyen BP, Pham HN, Tran H, et al. Predicting the onset of type 2 diabetes using wide and deep learning with electronic health records. Comput Methods Programs Biomed. 2019;182:105055. doi: https://doi.org/10.1016/j.cmpb.2019.105055
20. Lai H, Huang H, Keshavjee K, et al. Predictive models for diabetes mellitus using machine learning techniques. BMC Endocr Disord. 2019;19(1):101. doi: https://doi.org/10.1186/s12902-019-0436-6
21. Xiong XL, Zhang RX, Bi Y, et al. Machine Learning Models in Type 2 Diabetes Risk Prediction: Results from a Cross-sectional Retrospective Study in Chinese Adults. Curr Med Sci. 2019;39(4):582-588. doi: https://doi.org/10.1007/s11596-019-2077-4
22. Liao X, Kerr D, Morales J, Duncan I. Application of Machine Learning to Identify Clustering of Cardiometabolic Risk Factors in U.S. Adults. Diabetes Technol Ther. 2019;21(5):245-253. doi: https://doi.org/10.1089/dia.2018.0390
23. Dinh A, Miertschin S, Young A, Mohanty SD. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med Inform Decis Mak. 2019;19(1):211. doi: https://doi.org/10.1186/s12911-019-0918-5
24. Panaretos D, Koloverou E, Dimopoulos AC, et al. A comparison of statistical and machine-learning techniques in evaluating the association between dietary patterns and 10-year cardiometabolic risk (2002-2012): the ATTICA study. Br J Nutr. 2018;120(3):326-334. doi: https://doi.org/10.1017/S0007114518001150
25. Bernardini M, Romeo L, Misericordia P, Frontoni E. Discovering the Type 2 Diabetes in Electronic Health Records Using the Sparse Balanced Support Vector Machine. IEEE J Biomed Health Inform. 2020;24(1):235-246. doi: https://doi.org/10.1109/JBHI.2019.2899218
26. Chen P, Pan C. Diabetes classification model based on boosting algorithms. BMC Bioinformatics. 2018;19(1):109. doi: https://doi.org/10.1186/s12859-018-2090-9
27. Spänig S, Emberger-Klein A, Sowa JP, et al. The virtual doctor: An interactive clinical-decision-support system based on deep learning for non-invasive prediction of diabetes. Artif Intell Med. 2019;100:101706. doi: https://doi.org/10.1016/j.artmed.2019.101706
28. Al-Jarrah MA, Shatnawi H. Non-proliferative diabetic retinopathy symptoms detection and classification using neural network. J Med Eng Technol. 2017;41(6):498-505. doi: https://doi.org/10.1080/03091902.2017.1358772
29. Sayres R, Taly A, Rahimy E, et al. Using a Deep Learning Algorithm and Integrated Gradients Explanation to Assist Grading for Diabetic Retinopathy. Ophthalmology. 2019;126(4):552-564. doi: https://doi.org/10.1016/j.ophtha.2018.11.016
30. Wang XN, Dai L, Li ST, et al. Automatic Grading System for Diabetic Retinopathy Diagnosis Using Deep Learning Artificial Intelligence Software [published online ahead of print, 2020 May 15]. Curr Eye Res. 2020;1-6. doi: https://doi.org/10.1080/02713683.2020.1764975
31. Simões PW, Dos Passos MG, Amaral LL, et al. Meta-Analysis of the Sensitivity of Decision Support Systems in Diagnosing Diabetic Retinopathy. Stud Health Technol Inform. 2019;264:878-882. doi: https://doi.org/10.3233/SHTI190349
32. Shah A, Clarida W, Amelon R, et al. Validation of Automated Screening for Referable Diabetic Retinopathy With an Autonomous Diagnostic Artificial Intelligence System in a Spanish Population. J Diabetes Sci Technol. March 2020:193229682090621. doi: https://doi.org/10.1177/1932296820906212
33. Sosale B, Aravind SR, Murthy H, et al. Simple, Mobile-based Artificial Intelligence Algorithm in the detection of Diabetic Retinopathy (SMART) study. BMJ Open Diabetes Res Care. 2020;8(1):e000892. doi: https://doi.org/10.1136/bmjdrc-2019-000892
34. Rodriguez-Romero V, Bergstrom RF, Decker BS, et al. Prediction of Nephropathy in Type 2 Diabetes: An Analysis of the ACCORD Trial Applying Machine Learning Techniques. Clin Transl Sci. 2019;12(5):519-528. doi: https://doi.org/10.1111/cts.12647
35. Makino M, Yoshimoto R, Ono M, et al. Artificial intelligence predicts the progression of diabetic kidney disease using big data machine learning. Sci Rep. 2019;9(1):11862. doi: https://doi.org/10.1038/s41598-019-48263-5
36. Dagliati A, Marini S, Sacchi L, et al. Machine Learning Methods to Predict Diabetes Complications. J Diabetes Sci Technol. 2018;12(2):295-302. doi: https://doi.org/10.1177/1932296817706375
37. Williams BM, Borroni D, Liu R, et al. An artificial intelligence-based deep learning algorithm for the diagnosis of diabetic neuropathy using corneal confocal microscopy: a development and validation study. Diabetologia. 2020;63(2):419-430. doi: https://doi.org/10.1007/s00125-019-05023-4
38. Alaa AM, Bolton T, Di Angelantonio E, et al. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS One. 2019;14(5):e0213653. doi:10.1371/journal.pone.0213653
39. Kim E, Caraballo PJ, Castro MR, et al. Towards more Accessible Precision Medicine: Building a more Transferable Machine Learning Model to Support Prognostic Decisions for Micro- and Macrovascular Complications of Type 2 Diabetes Mellitus. J Med Syst. 2019;43(7):185. doi: https://doi.org/10.1007/s10916-019-1321-6
40. Карпельев В.А., Филиппов Ю.И., Тарасов Ю.В., и др. Математическое моделирование системы регуляции гликемии у пациентов с сахарным диабетом // Вестник РАМН. — 2015. — Т. 70. — №5. — С. 549-560. doi: https://doi.org/10.15690/vramn.v70.i5.1441.
41. Contreras I, Vehi J. Artificial Intelligence for Diabetes Management and Decision Support: Literature Review. J Med Internet Res. 2018;20(5):e10775. doi: https://doi.org/10.2196/10775
42. Rodríguez-Rodríguez I, Chatzigiannakis I, Rodríguez JV, et al. Utility of Big Data in Predicting Short-Term Blood Glucose Levels in Type 1 Diabetes Mellitus Through Machine Learning Techniques. Sensors (Basel). 2019;19(20):4482. doi: https://doi.org/10.3390/s19204482
43. Hidalgo JI, Colmenar JM, Kronberger G, et al. Data Based Prediction of Blood Glucose Concentrations Using Evolutionary Methods. J Med Syst. 2017;41(9):142. doi: https://doi.org/10.1007/s10916-017-0788-2
44. Oviedo S, Contreras I, Quirós C, et al. Risk-based postprandial hypoglycemia forecasting using supervised learning. Int J Med Inform. 2019;126:1-8. doi: https://doi.org/10.1016/j.ijmedinf.2019.03.008
45. Mirshekarian S, Bunescu R, Marling C, Schwartz F. Using LSTMs to learn physiological models of blood glucose behavior. Conf Proc IEEE Eng Med Biol Soc. 2017;2017:2887-2891. doi: https://doi.org/10.1109/EMBC.2017.8037460
46. Mosquera-Lopez C, Dodier R, Tyler NS, et al. Predicting and Preventing Nocturnal Hypoglycemia in Type 1 Diabetes Using Big Data Analytics and Decision Theoretic Analysis. Diabetes Technol Ther. 2020;22(11):801-811. doi: https://doi.org/10.1089/dia.2019.0458
47. Mayo M, Chepulis L, Paul RG. Glycemic-aware metrics and oversampling techniques for predicting blood glucose levels using machine learning. PLoS One. 2019;14(12):e0225613. doi: https://doi.org/10.1371/journal.pone.0225613
48. Seo W, Lee YB, Lee S, et al. A machine-learning approach to predict postprandial hypoglycemia. BMC Med Inform Decis Mak. 2019;19(1):210. doi: https://doi.org/10.1186/s12911-019-0943-4
49. Oviedo S, Contreras I, Bertachi A, et al. Minimizing postprandial hypoglycemia in Type 1 diabetes patients using multiple insulin injections and capillary blood glucose self-monitoring with machine learning techniques. Comput Methods Programs Biomed. 2019;178:175-180. doi: https://doi.org/10.1016/j.cmpb.2019.06.025
50. Rodríguez-Rodríguez I, Rodríguez J-V, Chatzigiannakis I, Zamora Izquierdo M. On the Possibility of Predicting Glycaemia ‘On the Fly’ with Constrained IoT Devices in Type 1 Diabetes Mellitus Patients. Sensors. 2019;19(20):4538. doi: https://doi.org/10.3390/s19204538
51. Biester T, Kordonouri O, Holder M, et al. «Let the Algorithm Do the Work»: Reduction of Hypoglycemia Using Sensor-Augmented Pump Therapy with Predictive Insulin Suspension (SmartGuard) in Pediatric Type 1 Diabetes Patients. Diabetes Technol Ther. 2017;19(3):173-182. doi: https://doi.org/10.1089/dia.2016.0349
52. Bosi E, Choudhary P, de Valk HW, et al. Efficacy and safety of suspend-before-low insulin pump technology in hypoglycaemia-prone adults with type 1 diabetes (SMILE): an open-label randomised controlled trial. Lancet Diabetes Endocrinol. 2019;7(6):462-472. doi: https://doi.org/10.1016/S2213-8587(19)30150-0
53. Saunders A, Messer LH, Forlenza GP. MiniMed 670G hybrid closed loop artificial pancreas system for the treatment of type 1 diabetes mellitus: overview of its safety and efficacy. Expert Rev Med Devices. 2019;16(10):845-853. doi: https://doi.org/10.1080/17434440.2019.1670639
54. Lepore G, Scaranna C, Corsi A, et al. Switching from Suspend-Before-Low Insulin Pump Technology to a Hybrid Closed-Loop System Improves Glucose Control and Reduces Glucose Variability: A Retrospective Observational Case-Control Study. Diabetes Technol Ther. 2020;22(4):321-325. doi: https://doi.org/10.1089/dia.2019.0302
55. Boughton CK, Hovorka R. The artificial pancreas. Curr Opin Organ Transplant. 2020;25(4):336-342. doi: https://doi.org/10.1097/MOT.0000000000000786
56. Lee S, Kim J, Park SW, et al. Toward a Fully Automated Artificial Pancreas System Using a Bioinspired Reinforcement Learning Design: In Silico Validation. IEEE J Biomed Heal Informatics. 2021;25(2):536-546. doi: https://doi.org/10.1109/JBHI.2020.3002022
57. Fico G, Arredondo MT. Use of an holistic approach for effective adoption of User-Centred-Design techniques in diabetes disease management: Experiences in user need elicitation. Conf Proc IEEE Eng Med Biol Soc. 2015;2015:2139-2142. doi: https://doi.org/10.1109/EMBC.2015.7318812
58. Tyler NS, Mosquera-Lopez CM, Wilson LM, et al. An artificial intelligence decision support system for the management of type 1 diabetes. Nat Metab. 2020;2(7):612-619. doi: https://doi.org/10.1038/s42255-020-0212-y
59. Rigla M, Martínez-Sarriegui I, García-Sáez G, et al. Gestational Diabetes Management Using Smart Mobile Telemedicine. J Diabetes Sci Technol. 2018;12(2):260-264. doi: https://doi.org/10.1177/1932296817704442
60. Caballero-Ruiz E, García-Sáez G, Rigla M, et al. A web-based clinical decision support system for gestational diabetes: Automatic diet prescription and detection of insulin needs. Int J Med Inform. 2017;102:35-49. doi: https://doi.org/10.1016/j.ijmedinf.2017.02.014
61. Alotaibi MM, Istepanian R, Philip N. A mobile diabetes management and educational system for type-2 diabetics in Saudi Arabia (SAED). Mhealth. 2016;2:33–33. doi: https://doi.org/10.21037/mhealth.2016.08.01
62. Hempe JM, Liu S, Myers L, et al. The Hemoglobin Glycation Index Identifies Subpopulations With Harms or Benefits From Intensive Treatment in the ACCORD Trial. Diabetes Care. 2015;38(6):1067-1074. doi: https://doi.org/10.2337/dc14-1844
63. Basu S, Raghavan S, Wexler DJ, Berkowitz SA. Characteristics Associated With Decreased or Increased Mortality Risk From Glycemic Therapy Among Patients With Type 2 Diabetes and High Cardiovascular Risk: Machine Learning Analysis of the ACCORD Trial. Diabetes Care. 2018;41(3):604-612. doi: https://doi.org/10.2337/dc17-2252
64. Pettus J, Roussel R, Liz Zhou F, et al. Rates of Hypoglycemia Predicted in Patients with Type 2 Diabetes on Insulin Glargine 300 U/ml Versus First- and Second-Generation Basal Insulin Analogs: The Real-World LIGHTNING Study. Diabetes Ther. 2019;10(2):617-633. doi: https://doi.org/10.1007/s13300-019-0568-8
65. Bosnyak Z, Zhou FL, Jimenez J, Berria R. Predictive Modeling of Hypoglycemia Risk with Basal Insulin Use in Type 2 Diabetes: Use of Machine Learning in the LIGHTNING Study. Diabetes Ther. 2019;10(2):605-615. doi: https://doi.org/10.1007/s13300-019-0567-9
66. Johnston SS, Morton JM, Kalsekar I, et al. Using Machine Learning Applied to Real-World Healthcare Data for Predictive Analytics: An Applied Example in Bariatric Surgery. Value Health. 2019;22(5):580-586. doi: https://doi.org/10.1016/j.jval.2019.01.011
Климонтов Вадим Валерьевич - доктор медицинских наук; eLibrary SPIN: 1734-4030.
630060, Новосибирск, ул. Тимакова, д.2
Конфликт интересов отсутствует
Бериков Владимир Борисович – доктор технических наук, ведущий научный сотрудник, eLibrary SPIN: 8108-2591.
Новосибирск
Конфликт интересов отсутствует
Сайк Ольга Владимировна - кандидат биологических наук, научный сотрудник; eLibrary SPIN: 6702-1490.
Новосибирск
Конфликт интересов отсутствует
Климонтов В.В., Бериков В.Б., Сайк О.В. Искусственный интеллект в диабетологии. Сахарный диабет. 2021;24(2):156-166. https://doi.org/10.14341/DM12665
Klimontov V.V., Berikov V.B., Saik O.V. Artificial intelligence in diabetology. Diabetes mellitus. 2021;24(2):156-166. (In Russ.) https://doi.org/10.14341/DM12665
 |
Адрес: 117036, Российская Федерация, Москва, улица Дмитрия Ульянова, дом 11.
Обработка персональных данных







































